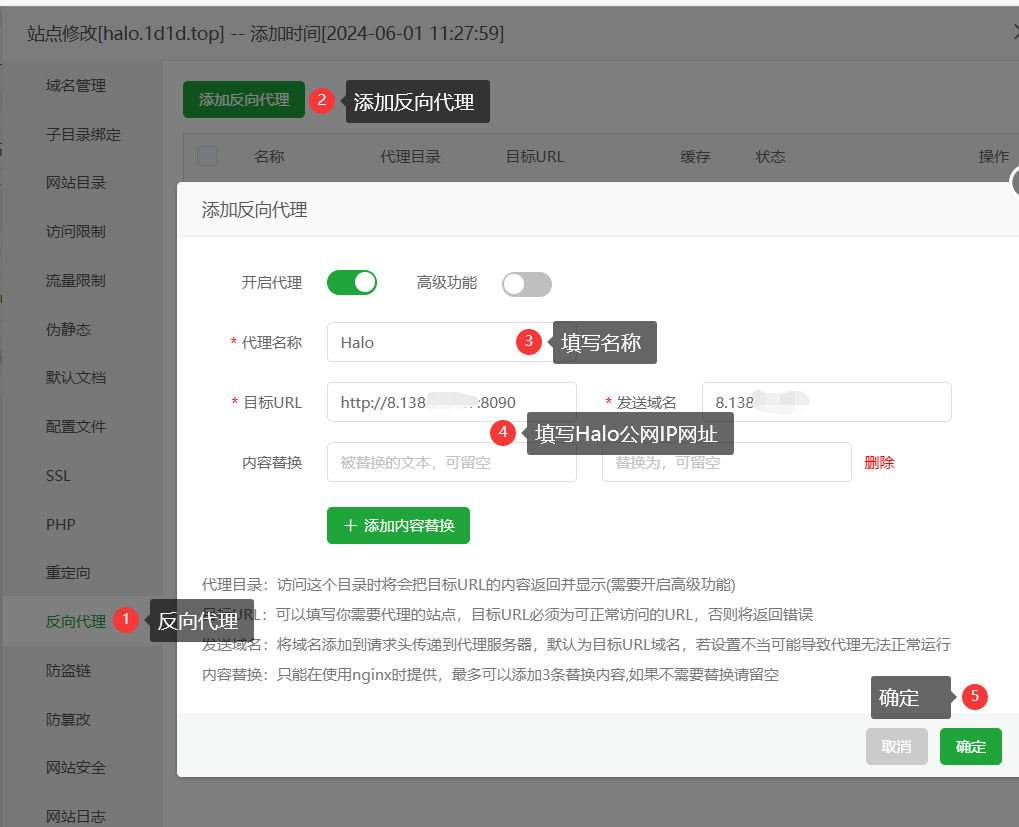
背景
- 基于 Transformer 的语言模型 (LM) 是现代 NLP 模型的支柱,但其内部预测构建过程不透明。这对于不了解模型为何做出特定预测的最终用户以及希望调试或修复模型行为的开发人员来说都是个问题
- 用于检查和干预基于转换器的语言模型的交互式工具
- 项目地址: https://github.com/mega002/lm-debugger
- 论文地址:https://arxiv.org/pdf/2204.12130#/
应用场景
这一工具在多个领域展现出广泛的应用潜力:
- 科研人员:可以更直观地研究模型如何理解和生成文本。
- 开发者:能快速定位并修正模型中的偏误或不一致性。
- 教育界:利用其作为教学工具,展示语言模型的工作原理。
- 企业:进行模型审计,确保AI产品的公平性和准确性。
项目特点
- 互动性强:允许用户直接修改模型预测结果,理解每一步决策背后的逻辑。
- 双重视角:提供调试和干预预测的界面以及探索模型内部编码信息的功能。
- 高度自定义:不仅限于GPT-2,易于适应其他Transformer架构。
- 学术支持:伴随论文详细解析,保证工具的科学性和可靠性
部署
- clone
git clone https://github.com/mega002/lm-debugger
cd lm-debugger
- 安装依赖
pip install -r requirements.txt
- 编译前端
cd ui
nvm install
yarn install
cd ..
- 部署es
version: '3.2'
services:
elasticsearch:
image: es:8.14.1
restart: always
environment:
# 开启内存锁定
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
# 指定单节点启动
- discovery.type=single-node
- xpack.security.http.ssl.enabled=false
- xpack.security.enabled=false
- ELASTIC_PASSWORD=
ulimits:
# 取消内存相关限制 用于开启内存锁定
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
- 准备模型文件
from modelscope import snapshot_download
model_dir = snapshot_download('AI-ModelScope/gpt2-medium')
- 修改配置文件
{
server_files_dir:: "/root/.cache/gpt2-medium/",
model_name:"/root/.cache/modelscope/hub/AI-ModelScope/gpt2-medium",
name:"gpt2-medium",
device:"cpu",
server_ip:"10.12.116.250",
server_port:8888,
elastic_ip:"10.12.116.250",
elastic_port:9200,
react_ip:"10.12.116.250",
react_port:9999,
streamlit_ip:"10.12.116.250",
streamlit_port:7777,
top_k_tokens_for_ui:10,
top_k_for_elastic:50,
create_cluster_files:false,
num_clusters:3000,
num_layers:24,
elastic_index:$.name + "_projections_docs",
elastic_projections_path:$.server_files_dir + "values_logits_" + $.name +"_top_"+$.top_k_for_elastic + ".pkl",
streamlit_cluster_to_value_file_path: $.server_files_dir + "cluster_to_value_" + $.name +"_num_clusters_"+$.num_clusters + ".pkl",
streamlit_value_to_cluster_file_path: $.server_files_dir + "value_to_cluster_" + $.name +"_num_clusters_"+$.num_clusters + ".pkl",
}
- 创建 Elasticsearch 索引
python es_index/index_value_projections_docs.py \
--config_path ./config_files/gpt2-medium.jsonnet
- 启动LM-Debugger
bash start.sh ./config_files/gpt2-medium.jsonnet
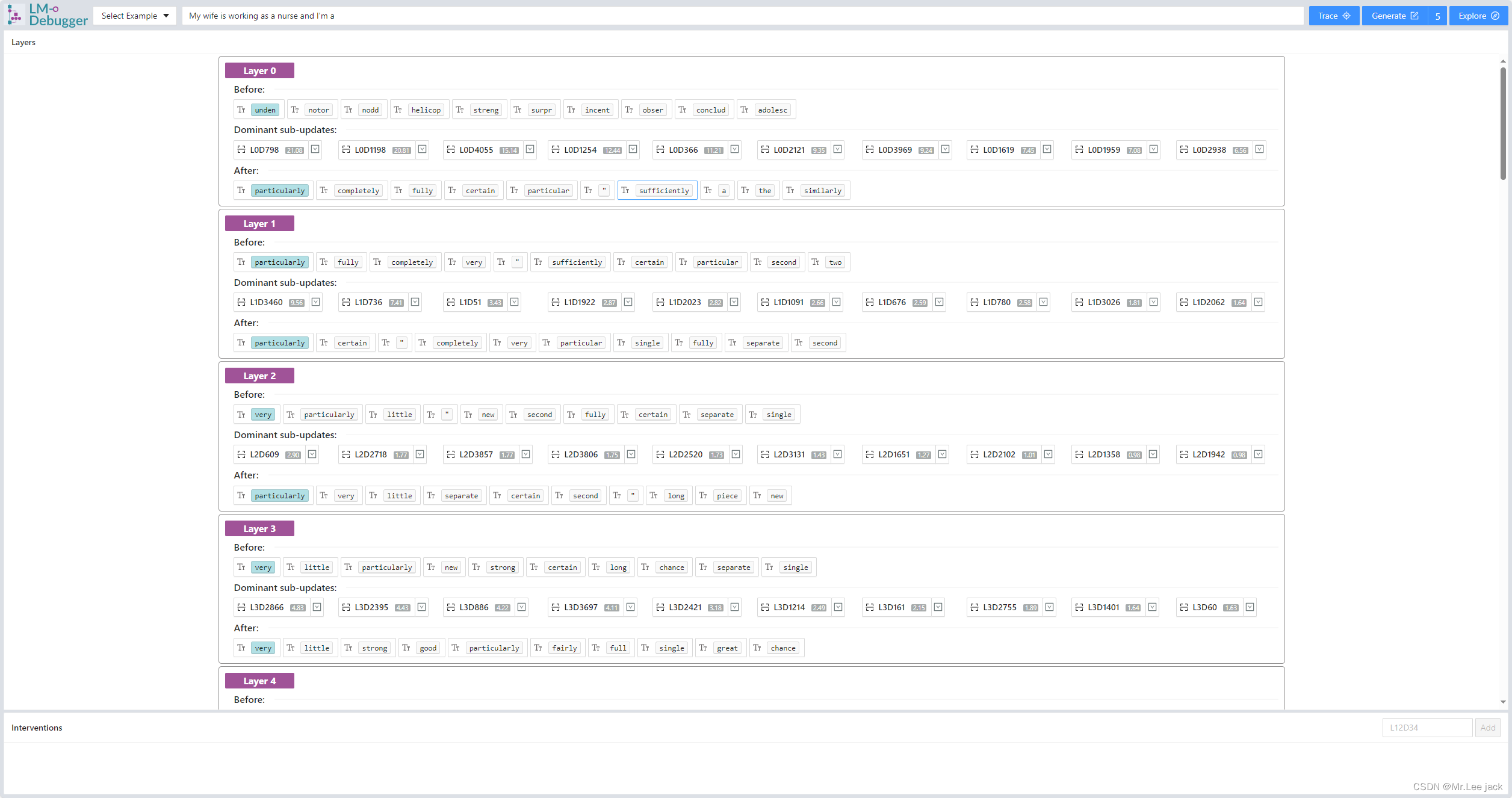
效果
原理
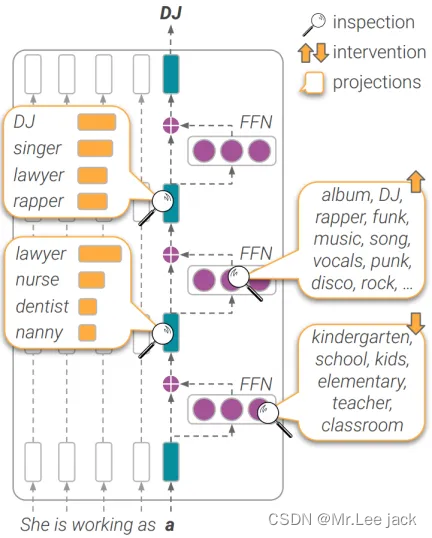
- 这篇论文的核心贡献是引入了LM-Debugger工具,通过分析和干预Transformer模型中的前馈神经网络(FFN)层来解释和控制模型的预测过程。以下是论文中关于为什么和如何实现干预以及工具的工作原理的详细解释。
为什么可以干预结果
论文中提出了一种方法,通过解释和干预Transformer模型内部的FFN层来实现对模型预测的控制。这种干预之所以可行,主要基于以下几点:
FFN层的贡献:
- FFN层是Transformer模型中的关键组成部分,负责对每个token表示进行变换和更新。
- 这些更新可以被分解为多个子更新,每个子更新由一个固定的参数向量(称为“值向量”)和一个输入依赖的权重系数(激活系数)构成。
子更新的解释性:
- 每个子更新对模型最终预测的影响可以通过将其投影到词汇空间来解释,即可以观察每个子更新在词汇空间中推广的top-token。
- 通过识别这些值向量及其对应的子更新,可以理解模型在每一层中如何逐步构建最终的输出分布。
干预机制:
- 可以通过修改这些子更新的权重系数来干预模型的预测过程。
- 具体而言,通过增加或减少某些特定子更新的权重,可以引导模型在某些特定方向上进行预测,从而达到干预预测结果的目的。
工具的解释机制
LM-Debugger工具通过以下几种主要功能来解释参数和数据流向:
预测视图(Prediction View):
- 该视图用于逐层跟踪和调试单次预测的内部过程。
- 用户可以输入一个句子,工具会显示模型在每一层的输出分布,以及FFN更新对这些分布的主要影响。
- 工具展示了每层之前和之后的token分布变化,以及对这些变化贡献最大的10个子更新。
干预设置(Interventions):
- 用户可以在预测过程中设置干预,通过指定值向量及其对应的子更新来修改模型的预测。
- 干预可以是“打开”或“关闭”某个值向量,即设置其激活系数为某个最大值或为零。
值向量信息(Value Vector Information):
- 用户可以查看特定值向量的top-token,帮助理解这些值向量在词汇空间中推广的概念。
- 工具允许用户为值向量分配名称,以便于管理和理解。
探索视图(Exploration View):
- 该视图用于静态探索模型中所有值向量,分析FFN层中编码的概念以及这些概念在不同层中的分布情况。
- 用户可以通过关键词搜索找到与特定概念相关的值向量,并通过聚类可视化找到相关值向量的群组。
干预示例
以下是如何使用LM-Debugger工具进行干预的具体示例:
- 职业预测干预:
- 输入句子“我的妻子是”。
- 原始模型可能输出“护士、教师、服务员”等职业。
- 通过在探索视图中搜索与“软件工程师”相关的值向量,并将这些值向量添加到干预面板中,重新生成预测,输出可能会变为“软件工程师、程序员、开发人员”等。
- 情感控制:
- 输入句子“服务太差”。
- 原始模型可能生成负面评论。
- 通过搜索与积极和消极情感相关的值向量,并分别设置干预,可以控制生成的文本带有积极或消极的情感色彩。
干预的具体步骤
选择干预目标:
- 用户首先需要选择要干预的具体层以及该层中的特定值向量(value vector)。
- 每个FFN层可以被视为由多个值向量组成,这些向量通过非线性变换和输入依赖的激活系数影响模型的输出。
确定值向量和子更新:
- 通过预测视图,用户可以查看每一层的主要子更新。这些子更新是由特定值向量和其对应的激活系数组成的。
- 工具展示了这些子更新在词汇空间中的top-token,从而帮助用户理解每个值向量对预测结果的贡献。
配置干预:
- 用户可以在工具的干预面板中输入特定的值向量标识符,并选择“打开”或“关闭”该向量的子更新。
- “打开”某个值向量意味着将其激活系数设置为该层中最显著的子更新系数,从而最大化该值向量的影响。
- “关闭”某个值向量则是将其激活系数设置为零,从而消除该值向量对输出的影响。
执行干预:
- 一旦配置好干预,用户可以重新运行输入数据,工具会在整个生成过程中应用这些干预。
- 工具会根据用户配置的干预调整每一层的输出分布,最终影响模型的预测结果
如何适配其他模型
import json
import warnings
import numpy as np
import torch
import torch_gcu
import torch.nn.functional as F
from create_offline_files import create_elastic_search_data, create_streamlit_data
from transformers import GPT2Tokenizer, GPT2LMHeadModel
warnings.filterwarnings('ignore')
class ModelingRequests():
def __init__(self, args):
self.model = GPT2LMHeadModel.from_pretrained(args.model_name,torch_dtype=torch.float32)
self.device = args.device
self.model.to(self.device)
self.tokenizer = GPT2Tokenizer.from_pretrained(args.model_name)
self.dict_es = create_elastic_search_data(args.elastic_projections_path, self.model, args.model_name,
self.tokenizer, args.top_k_for_elastic)
if args.create_cluster_files:
create_streamlit_data(args.streamlit_cluster_to_value_file_path, args.streamlit_value_to_cluster_file_path,
self.model, args.model_name, args.num_clusters)
self.TOP_K = args.top_k_tokens_for_ui
def set_control_hooks_gpt2(self, values_per_layer, coef_value=0):
def change_values(values, coef_val):
def hook(module, input, output):
output[:, :, values] = coef_val
pass
return hook
hooks = []
for l in range(self.model.config.n_layer):
if l in values_per_layer:
values = values_per_layer[l]
else:
values = []
hook = self.model.transformer.h[l].mlp.c_fc.register_forward_hook(
change_values(values, coef_value)
)
hooks.append(hook)
return hooks
def remove_hooks(self, hooks):
for hook in hooks:
hook.remove()
def set_hooks_gpt2(self):
final_layer = self.model.config.n_layer - 1
for attr in ["activations_"]:
if not hasattr(self.model, attr):
setattr(self.model, attr, {})
def get_activation(name):
def hook(module, input, output):
if "mlp" in name or "attn" in name or "m_coef" in name:
if "attn" in name:
num_tokens = list(output[0].size())[1]
self.model.activations_[name] = output[0][:, num_tokens - 1].detach()
elif "mlp" in name:
num_tokens = list(output[0].size())[0] # [num_tokens, 3072] for values;
self.model.activations_[name] = output[0][num_tokens - 1].detach()
elif "m_coef" in name:
num_tokens = list(input[0].size())[1] # (batch, sequence, hidden_state)
self.model.activations_[name] = input[0][:, num_tokens - 1].detach()
elif "residual" in name or "embedding" in name:
num_tokens = list(input[0].size())[1] # (batch, sequence, hidden_state)
if name == "layer_residual_" + str(final_layer):
self.model.activations_[name] = self.model.activations_[
"intermediate_residual_" + str(final_layer)] + \
self.model.activations_["mlp_" + str(final_layer)]
else:
self.model.activations_[name] = input[0][:,
num_tokens - 1].detach()
return hook
self.model.transformer.h[0].ln_1.register_forward_hook(get_activation("input_embedding"))
for i in range(self.model.config.n_layer):
if i != 0:
self.model.transformer.h[i].ln_1.register_forward_hook(get_activation("layer_residual_" + str(i - 1)))
self.model.transformer.h[i].ln_2.register_forward_hook(get_activation("intermediate_residual_" + str(i)))
self.model.transformer.h[i].attn.register_forward_hook(get_activation("attn_" + str(i)))
self.model.transformer.h[i].mlp.register_forward_hook(get_activation("mlp_" + str(i)))
self.model.transformer.h[i].mlp.c_proj.register_forward_hook(get_activation("m_coef_" + str(i)))
self.model.transformer.ln_f.register_forward_hook(get_activation("layer_residual_" + str(final_layer)))
def get_resid_predictions(self, sentence, start_idx=None, end_idx=None, set_mlp_0=False):
HIDDEN_SIZE = self.model.config.n_embd
layer_residual_preds = []
intermed_residual_preds = []
if start_idx is not None and end_idx is not None:
tokens = [
token for token in sentence.split(' ')
if token not in ['', '\n']
]
sentence = " ".join(tokens[start_idx:end_idx])
tokens = self.tokenizer(sentence, return_tensors="pt")
tokens.to(self.device)
output = self.model(**tokens, output_hidden_states=True)
for layer in self.model.activations_.keys():
if "layer_residual" in layer or "intermediate_residual" in layer:
normed = self.model.transformer.ln_f(self.model.activations_[layer])
logits = torch.matmul(self.model.lm_head.weight, normed.T)
probs = F.softmax(logits.T[0], dim=-1)
probs = torch.reshape(probs, (-1,)).detach().cpu().numpy()
print(probs)
assert np.abs(np.sum(probs) - 1) <= 0.01, str(np.abs(np.sum(probs) - 1)) + layer
probs_ = []
for index, prob in enumerate(probs):
probs_.append((index, prob))
top_k = sorted(probs_, key=lambda x: x[1], reverse=True)[:self.TOP_K]
top_k = [(t[1].item(), self.tokenizer.decode(t[0])) for t in top_k]
if "layer_residual" in layer:
layer_residual_preds.append(top_k)
elif "intermediate_residual" in layer:
intermed_residual_preds.append(top_k)
for attr in ["layer_resid_preds", "intermed_residual_preds"]:
if not hasattr(self.model, attr):
setattr(self.model, attr, [])
self.model.layer_resid_preds = layer_residual_preds
self.model.intermed_residual_preds = intermed_residual_preds
def get_preds_and_hidden_states(self, prompt):
self.set_hooks_gpt2()
sent_to_preds = {}
sent_to_hidden_states = {}
sentence = prompt[:]
self.get_resid_predictions(sentence)
sent_to_preds["layer_resid_preds"] = self.model.layer_resid_preds
sent_to_preds["intermed_residual_preds"] = self.model.intermed_residual_preds
sent_to_hidden_states = self.model.activations_.copy()
return sent_to_hidden_states, sent_to_preds
def process_and_get_data(self, prompt):
sent_to_hidden_states, sent_to_preds = self.get_preds_and_hidden_states(prompt)
records = []
top_coef_idx = []
top_coef_vals = []
residual_preds_probs = []
residual_preds_tokens = []
layer_preds_probs = []
layer_preds_tokens = []
for LAYER in range(self.model.config.n_layer):
coefs_ = []
m_coefs = sent_to_hidden_states["m_coef_" + str(LAYER)].squeeze(0).cpu().numpy()
res_vec = sent_to_hidden_states["layer_residual_" + str(LAYER)].squeeze(0).cpu().numpy()
value_norms = torch.linalg.norm(self.model.transformer.h[LAYER].mlp.c_proj.weight.data, dim=1).cpu()
scaled_coefs = np.absolute(m_coefs) * value_norms.numpy()
for index, prob in enumerate(scaled_coefs):
coefs_.append((index, prob))
top_values = sorted(coefs_, key=lambda x: x[1], reverse=True)[:self.TOP_K]
c_idx, c_vals = zip(*top_values)
top_coef_idx.append(c_idx)
top_coef_vals.append(c_vals)
residual_p_probs, residual_p_tokens = zip(*sent_to_preds['intermed_residual_preds'][LAYER])
residual_preds_probs.append(residual_p_probs)
residual_preds_tokens.append(residual_p_tokens)
layer_p_probs, layer_p_tokens = zip(*sent_to_preds['layer_resid_preds'][LAYER])
layer_preds_probs.append(layer_p_probs)
layer_preds_tokens.append(layer_p_tokens)
return {
"sent": prompt,
"top_coef_idx": top_coef_idx,
"top_coef_vals": top_coef_vals,
"residual_preds_probs": residual_preds_probs,
"residual_preds_tokens": residual_preds_tokens,
"layer_preds_probs": layer_preds_probs,
"layer_preds_tokens": layer_preds_tokens,
"layer_residual_vec": res_vec,
}
def process_pred_dict(self, pred_df):
pred_d = {}
pred_d['prompt'] = pred_df['sent']
pred_d['layers'] = []
for layer_n in range(self.model.config.n_layer):
layer_d = {}
layer_d['layer'] = layer_n
layer_d['predictions_before'] = [
{'token': pred_df['residual_preds_tokens'][layer_n][k],
'score': float(pred_df['residual_preds_probs'][layer_n][k])
}
for k in range(self.TOP_K)
]
layer_d['predictions_after'] = [
{'token': pred_df['layer_preds_tokens'][layer_n][k],
'score': float(pred_df['layer_preds_probs'][layer_n][k])
}
for k in range(self.TOP_K)
]
significant_values_lst = []
dims_layer_n = pred_df['top_coef_idx'][layer_n]
scores_layer_n = pred_df['top_coef_vals'][layer_n]
for k in range(self.TOP_K):
significant_values_lst.append(
{'layer': layer_n,
'dim': dims_layer_n[k],
'score': float(scores_layer_n[k])
}
)
layer_d['significant_values'] = significant_values_lst
pred_d['layers'].append(layer_d)
return pred_d
def json_req_to_prompt_and_interventions_d(self, req_json_path):
with open(req_json_path) as json_f:
req = json.load(json_f)
return [req['prompt']], req['interventions']
def process_clean_token(self, token):
return token
def get_new_max_coef(self, layer, old_dict, eps=10e-3):
curr_max_val = old_dict['top_coef_vals'][layer][0]
return curr_max_val + eps
def request2response(self, req_json_dict, save_json=False, res_json_path=None, res_json_intervention_path=None):
response_dict = {}
prompt, interventions_lst = req_json_dict['prompt'], req_json_dict['interventions']
pred_dict_raw = self.process_and_get_data(prompt)
pred_dict = self.process_pred_dict(pred_dict_raw)
response_dict['response'] = pred_dict
if len(interventions_lst) > 0:
hooks_lst = []
maxs_dict = {l: self.get_new_max_coef(l, pred_dict_raw) for l in range(self.model.config.n_layer)}
for intervention in interventions_lst:
if intervention['coeff'] > 0:
new_max_val = maxs_dict[intervention['layer']]
else:
new_max_val = 0
hooks_lst.append(self.set_control_hooks_gpt2({intervention['layer']: [intervention['dim']], },
coef_value=new_max_val))
pred_dict_new_raw = self.process_and_get_data(prompt)
pred_dict_new = self.process_pred_dict(pred_dict_new_raw)
response_dict['intervention'] = pred_dict_new
for hook in hooks_lst:
self.remove_hooks(hook)
return response_dict
def request2response_for_generation(self, req_json_dict, save_json=False, res_json_path=None,
res_json_intervention_path=None):
response_dict = {}
prompt, interventions_lst = req_json_dict['prompt'], req_json_dict['interventions']
pred_dict_raw = self.process_and_get_data(prompt)
if len(interventions_lst) > 0:
hooks_lst = []
maxs_dict = {l: self.get_new_max_coef(l, pred_dict_raw) for l in range(self.model.config.n_layer)}
for intervention in interventions_lst:
if intervention['coeff'] > 0:
new_max_val = maxs_dict[intervention['layer']]
else:
new_max_val = 0
hooks_lst.append(self.set_control_hooks_gpt2({intervention['layer']: [intervention['dim']], },
coef_value=new_max_val))
tokens = self.tokenizer(prompt, return_tensors="pt")
tokens.to(self.device)
greedy_output = self.model.generate(**tokens,
max_length=req_json_dict['generate_k'] + len(tokens['input_ids'][0]))
greedy_output = self.tokenizer.decode(greedy_output[0], skip_special_tokens=True)
response_dict['generate_text'] = greedy_output
if len(interventions_lst) > 0:
for hook in hooks_lst:
self.remove_hooks(hook)
return response_dict
def send_request_get_response(self, request_json_dict):
return self.request2response(request_json_dict,
save_json=False,
res_json_path=None,
res_json_intervention_path=None)
def send_request_get_response_for_generation(self, request_json_dict):
return self.request2response_for_generation(request_json_dict,
save_json=False,
res_json_path=None,
res_json_intervention_path=None)
def get_projections(self, layer, dim):
x = [(x[1], x[2]) for x in self.dict_es[(int(layer), int(dim))]]
new_d = {'layer': int(layer), 'dim': int(dim)}
top_k = [{'token': self.process_clean_token(x[i][0]), 'logit': float(x[i][1])} for i in range(len(x))]
new_d['top_k'] = top_k
return new_d
- 源码中可以知道,需要添加对应模型的
register_forward_hook - 对应层的映射关系
总结
通过LM-Debugger,用户可以细粒度地解释Transformer模型内部的预测构建过程,并通过识别和调整特定的FFN子更新来干预和控制模型的预测结果。工具提供了直观的可视化界面,使用户能够理解模型内部的参数和数据流向,并根据需要进行有效的干预。这种方法大大增强了模型的透明度和可控性